type
status
date
slug
summary
tags
category
icon
password
comment
大型语言模型(Large language models, LLMs)因其在学术界和工业界展现出前所未有的性能而备受青睐。随着 LLMs 在研究和实际应用中被广泛使用,对其进行有效评测变得愈发重要。
困惑度
衡量语言建模能力的重要指标,通过计算给定文本序列概率的倒数的几何平均,来衡量模型对于语言的建模能力。基础公式如下:
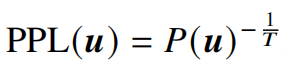
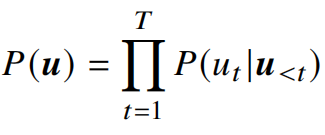
其中,u代表整个句子,T是文本u的单词总数。P(u)是模型对文本u的建模概率,𝑢𝑡 代表文本中的第 𝑡 个词元,𝑃(𝑢𝑡
|𝒖<𝑡) 则表示在给定前 𝑡 − 1 个词元的条件下第 𝑡 个词元出现的概率。
在实际应用中,为了避免计算中出现数值下溢,一般采用对数概率加和的方法。变换之后的公式如下:
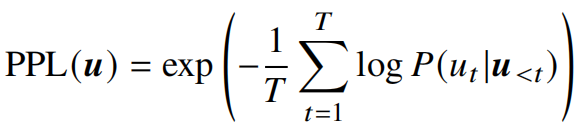
BLEU
是一种再机器翻译领域广泛采用的评估指标,通过度量模型生成的文本和参考文本之间的词汇相似度来评估生成质量。BLEU 主要计算候选文本与参考文本的 𝑛 元组(𝑛-gram)共现频率,评分结果在 [0, 1] 的区间内,
具体的计算方式如下所示:
Rouge-n
是一种再机器翻译和文本摘要评估中广泛使用的指标,主要强调文本信息的覆盖度和完整性。比如rouge-2度量模型生成的文本和“参考”之间匹配的“bigrams”的数量,示例如下:

Rouge-L
度量模型生成的文本和“参考”之间的最长公共子序列(LCS),用来衡量两个序列的相似性。
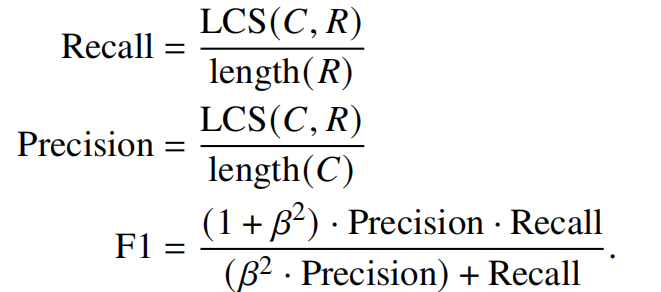
LCS(𝐶, 𝑅) 表示 𝐶 和 𝑅 之间的最长公共子序列长度。length(𝐶) 和length(𝑅) 分别代表候选文本和参考文本的长度。在 ROUGE-L 中,𝛽 用于决定召回率的权重。
准确率
计算模型预测正确的样本数占总样本数的比例,计算步骤如下:
1、假如答案是四个选项,模型会生成每个选项对应的概率。找出最大概率所在的位置,即可得到选项答案
2、用选项答案和数据集中的标准答案对比,记录正确的数据条数
3、计算准确率,用正确的数据条数除以所有数据条数。公式如下:
Acc=sum(正确)/sum(所有)
归一化准确率
作用和准确率一样,和准确率计算的第1步差异是:先对每个选项对应概率除以答案字符串长度,例如:
四个答案是:["Shady areas increased.","Food sources increased.","Oxygen levels increased.","Available water increased."]
模型直接生成的概率是[0.1, 0.4. 0.8, 0.2],归一化之后的概率是[0.1/len(Shady areas increased.), ....]
不同评价指标适用场景:
